前言
redis 作为目前流行的一个非关系数据库,在许多项目中承当着系统缓存等角色。这里,我们先来简单了解一下 redis。
导航
概述
一般认为 redis 属于 key-value 内存数据库。这里有两个关键值:一个是 key-value,一个是内存数据库。key-value 是非关系型数据库(NoSQL)的一种。非关系型数据库(NoSQL)全称 Not Only SQL:
2009 年,Last.fm 的 Johan Oskarsson 发起了一次关于分布式开源数据库的讨论[2],来自 Rackspace 的 Eric Evans 再次提出了 NoSQL 的概念,这时的 NoSQL 主要指非关系型、分布式、不提供 ACID 的数据库设计模式。
2009 年在亚特兰大举行的”no:sql(east)”讨论会是一个里程碑,其口号是”select fun, profit from real_world where relational=false;”。因此,对 NoSQL 最普遍的解释是“非关联型的”,强调键-值存储和面向文档数据库的优点,而不是单纯的反对 RDBMS。
但真实世界中不是所有事物都是适合“关系模型”的。这时候,NoSQL 就显得比较友好。NoSQL 的类型很多,如有文档型的 mongodb,图形型的 neo4j,还有 key-value 类型的 redis 等等。其中,key-value 型的数据库通常使用 hash table 实现,典型应用场景是缓存,比如大量数据的高访问负载,这也是 redis 的主要应用场景。
内存数据库则很好理解,就是将数据存储在内存、而不是存储磁盘的数据库。但存储在内存中相对容易丢失数据,所以 redis 也提供了持久化功能。
以上是常规的印象,接下来,我们来看看 redis 的官网是如何介绍的:
Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache, and message broker. Redis provides data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, geospatial indexes, and streams. Redis has built-in replication, Lua scripting, LRU eviction, transactions, and different levels of on-disk persistence, and provides high availability via Red and automatic partitioning with Redis Cluster.
这里介绍到 redis 是“基于内存的数据结构存储”,提供的数据结构包括 string、hash、list、set、sorted set,并且支持主从复制、lua 脚本、LRU(Least Recently Used,最近最少使用)淘汰、事务、持久化等。
对数据的持久化,redis 提供四种方式
- RDB (Redis Database):周期性快照,比如每隔 24h 做一次备份。RDB 文件非常紧凑所以适合备份。
- AOF (Append Only File):记录每次写操作,有三种记录模式:不追加、每秒追加、每次写追加。记录文件过大时会进行重写。
- No
- RDB + AOF
RDB 与 AOF 各有优劣,比如 RDB 可能会丢失较大时间段之内的数据,AOF 对性能的影响比 RDB 大(RDB 使用另一个进程去持久化)。
接下里,让我们通过 v1.2.6 版本主函数大体了解一下 redis。
主函数(v1.2.6 版本)
1 | int main(int argc, char **argv) { |
可以大体推测出其中用于处理事件的函数是 aeMain()函数,这个函数很简单:
1 | void aeMain(aeEventLoop *eventLoop) { |
所以 redis 会不断从 aeEventLoop 中接受事件并处理,那么 ae 又是什么呢?这个答案在 ae.h 里,文件中注释到:
A simple event-driven programming library.
也就是说,ae 是一个事件驱动的库。
事件驱动与 io 多路复用
事件驱动可以分成 mediator 与 broker 两种模式。mediator 模式中,每个事件将会先入队列,由 mediator 去将事件分发给相应的 channel,然后由 processor 处理器处理:
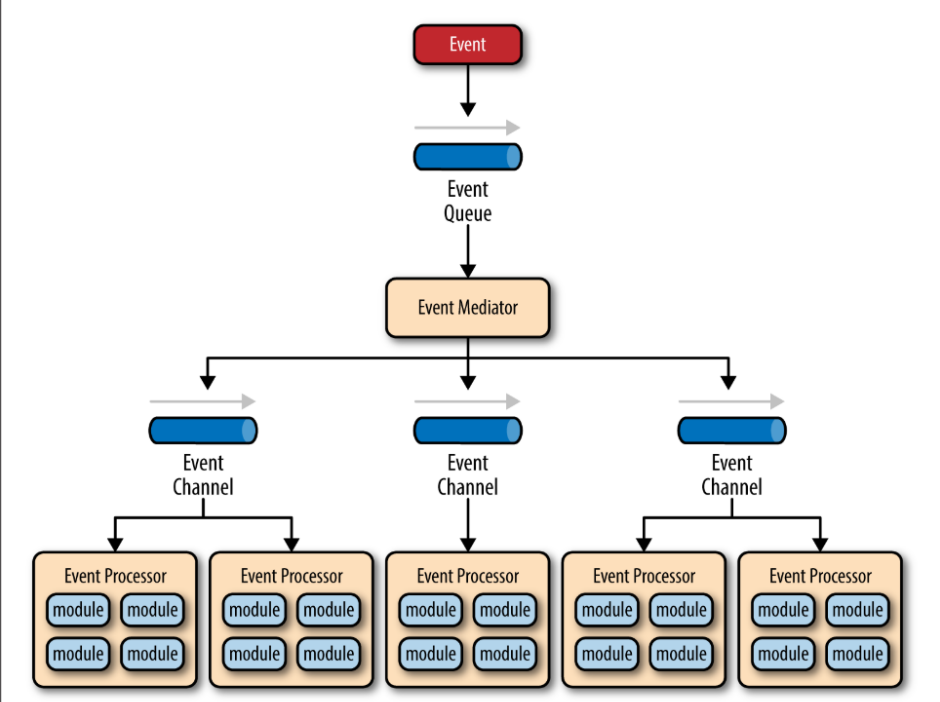
broker 模式则没有 mediator 来分发事件,事件直接被放入相应的 channel,然后由 processor 取出处理。与 medidator 模式不同的是,broker 模式中 processor 处理完事件之后,也许会向一些 channel 发送事件,供其他 processer 处理。
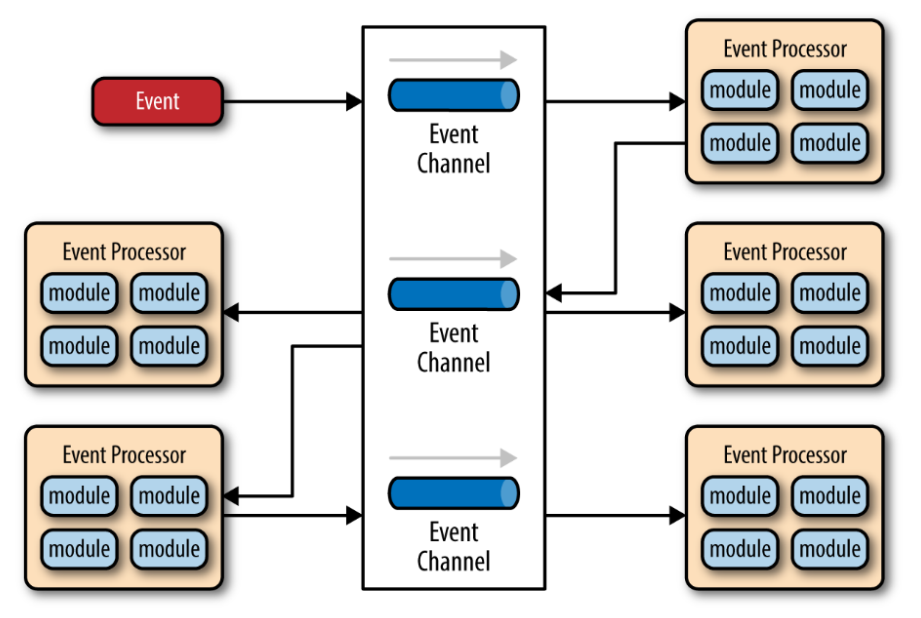
redis 采用的是 mediator 模式。至于如何实现的,我们从文件名就可以推测:
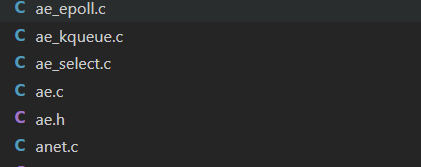
分别是 unix 所提供的 epoll、kqueue、select 函数:
1 | // ae.c |
这三个函数都是 io 复用的一种,在介绍在这些函数之前,让我们了解一下什么是 io 复用。
unix 下的 io 模型有这几种:
- 阻塞式
- 非阻塞式
- io 复用
- 信号驱动式(sigio)
- 异步 io
一个数据输入通常包括两个阶段,一是等待数据到达内核并且内核准备好复制数据,二是从内核将数据复制到进程。
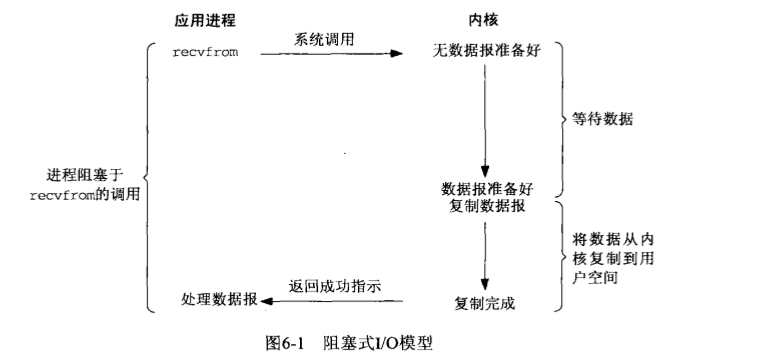
对于应用来说,阻塞式 io 完全等待了内核准备数据与数据复制的时间,所以使用阻塞式 io 的效率较低。非阻塞式 io 将这个等待的过程改为了轮询:
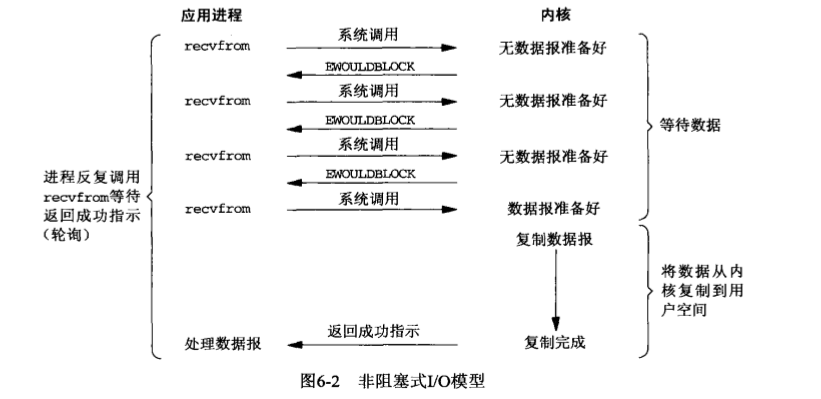
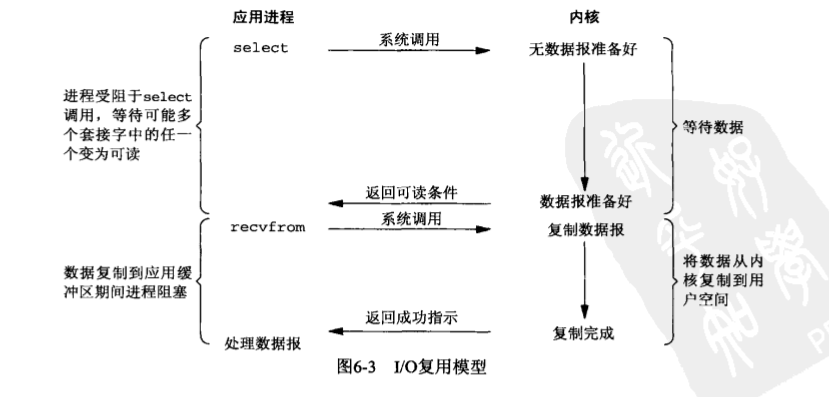
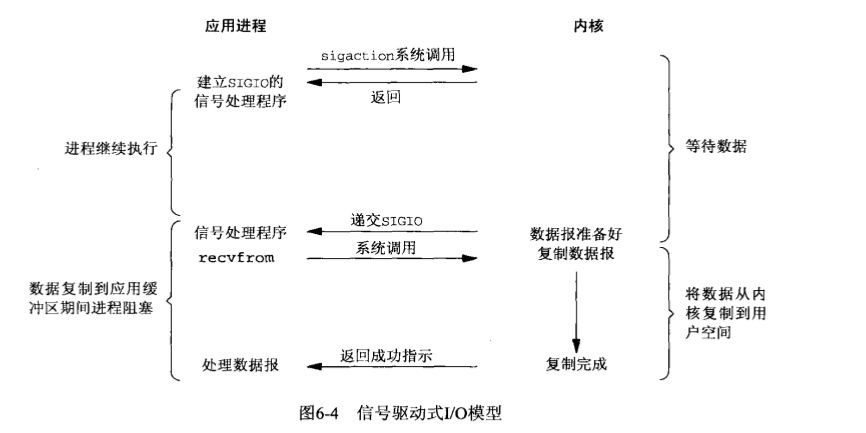
应用使用非阻塞式 io 时,需要采用轮询的方法去确定数据有没有准备好。而轮询往往会耗费大量的 cpu 时间。如果将应用程序主动询问内核数据是否准备好改成由内核通知应用程序是否准备好,那么就可以大量减少 cpu 消耗。io 复用与信号驱动式 io 就是如此:
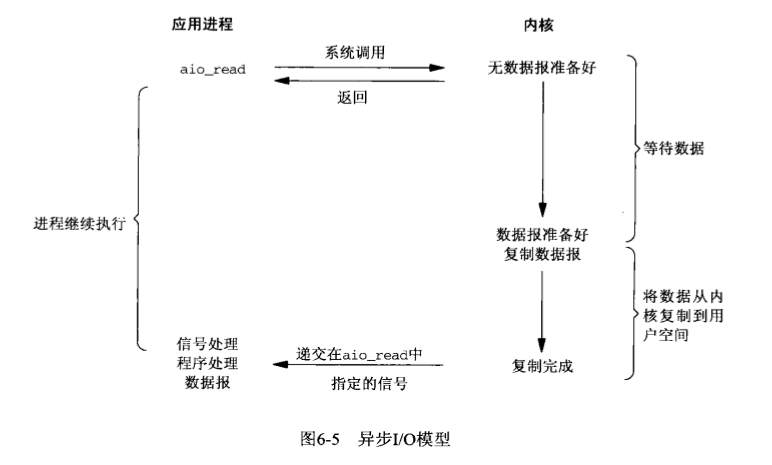
至于异步 io,则更进一步,不再通知应用程序可以进行 io 操作了,而是直接通知整个 io 是否完成:
目光放回 io 复用,其中的 io 复用函数(如 select)除了返回可读条件之外,还可以返回可写、异常、超时等,并且可以同时等待多个 fd,和事件驱动中负责分发事件的 mediator 角色非常相似。事实上,redis 也是利用 io 复用函数来实现事件驱动的。而 io 复用的函数,除了 select 之外,还有 epoll 与 kqueque。对于 select 来说,虽然能监听多个 fd,但并不知道是哪个 fd 产生了事件,应用程序只能通过无差别轮询所有 fd 才能对齐操作。epoll(linux)、kqueue(BSD)函数改进了这点,让应用程序可以知晓是哪个 fd 产生的。
所以利用 io 复用,可以将 io 阻塞部分转移出应用层面,提高应用执行效率。
了解了这些,再看 aeProcessEvents()中的文件事件处理,就很容易理解了:
1 | numevents = aeApiPoll(eventLoop, tvp); // 产生io事件的fd数量 |
aeEventLoop 事件循环结构:
1 | typedef struct aeEventLoop { |